
Natural language processing (NLP), while hardly a new discipline, has catapulted into the public consciousness these past few months thanks in large part to the generative AI hype train that is ChatGPT. Alongside other NLP models such as Hugging Face’s Transformers, and Google’s LaMDA which is set to power its ChatGPT-rival Bard, there’s a palpable feeling that AI’s arrival into the mainstream is almost here.
But for those punching a few keywords into ChatGPT to make it create lyrics in the style of Nick Cave, it’s easy to overlook all the work that goes into developing the underlying AI models, getting them to the point where they are ready for mass-market consumption.
To create NLP models, developers need not only algorithms, but bucketloads of quality training data that is accurately “labelled,” a technique that categorizes raw data to enable machines to understand and learn from it. Numerous companies exist substantively to power this labelling process, one of which is German startup Kern AI, which has built a platform for NLP developers and data scientists to not only control the labelling process, but automate and orchestrate tangential tasks and allow them to address low-quality data that comes their way.
‘Data-centric’ NLP
With NLP one of the hot AI trends of the moment, Kern AI today announced that it has raised €2.7 million ($2.9 million) in seed funding to double-down on recent growth that has seen it adopted by commercial clients including insurance companies Barmenia and VHV Versicherungen, logistics firms such as Metro Supply Chain Group subsidiary Evolution Time Critical, and venture-backed startups such as Crowd.dev. The company also says that its basic open source incarnation has been used by data scientists at companies such as Samsung and DocuSign.
Founded out of Bonn in 2020, co-founder and CEO Johannes Hötter said that he started the company “with the belief that NLP will turn into a core digitization technology,” acknowledging that developers need more control and flexibility over the NLP development process.
The company’s flagship product is the open source Refinery, which allows developers to adopt a data-centric approach to building NLP models through semi-automating their labelling, identify low-quality datasets in their training data, and monitor all their data in a single interface.
Elsewhere, Bricks — also open source — is a collection of modular, standardized “code snippets” that developers can integrate into Refinery — it’s the “application logic driving your NLP automations,” according to the company.
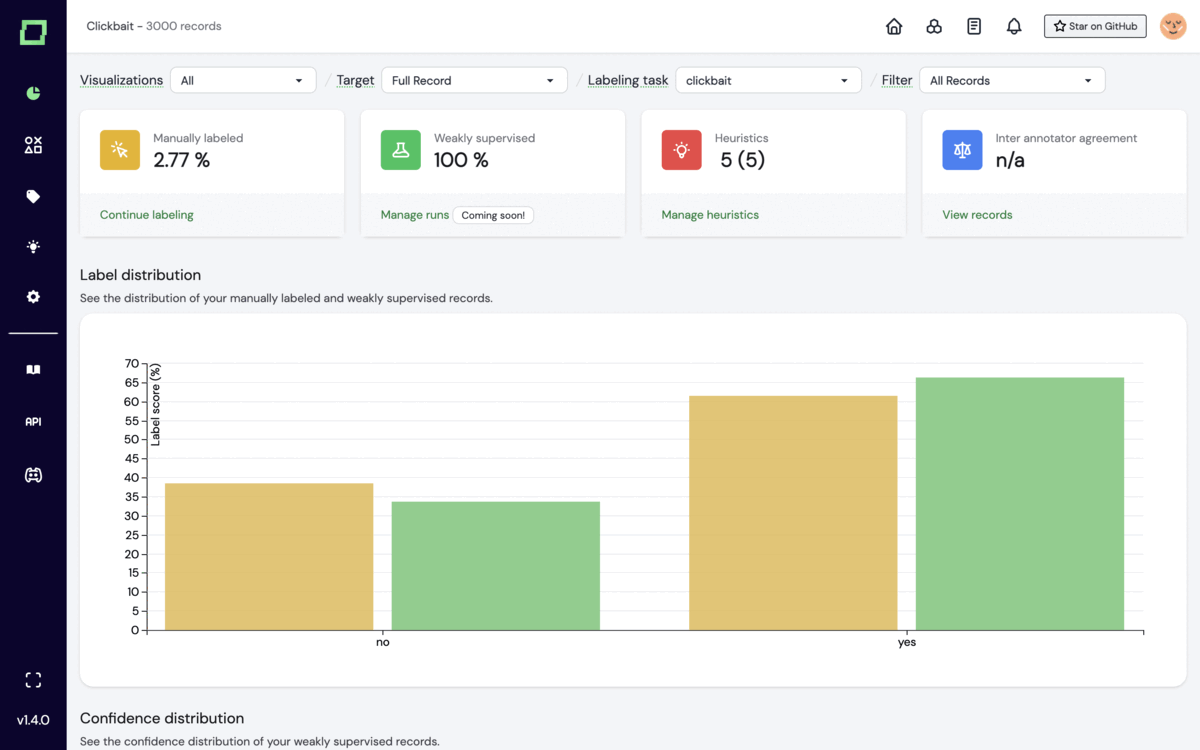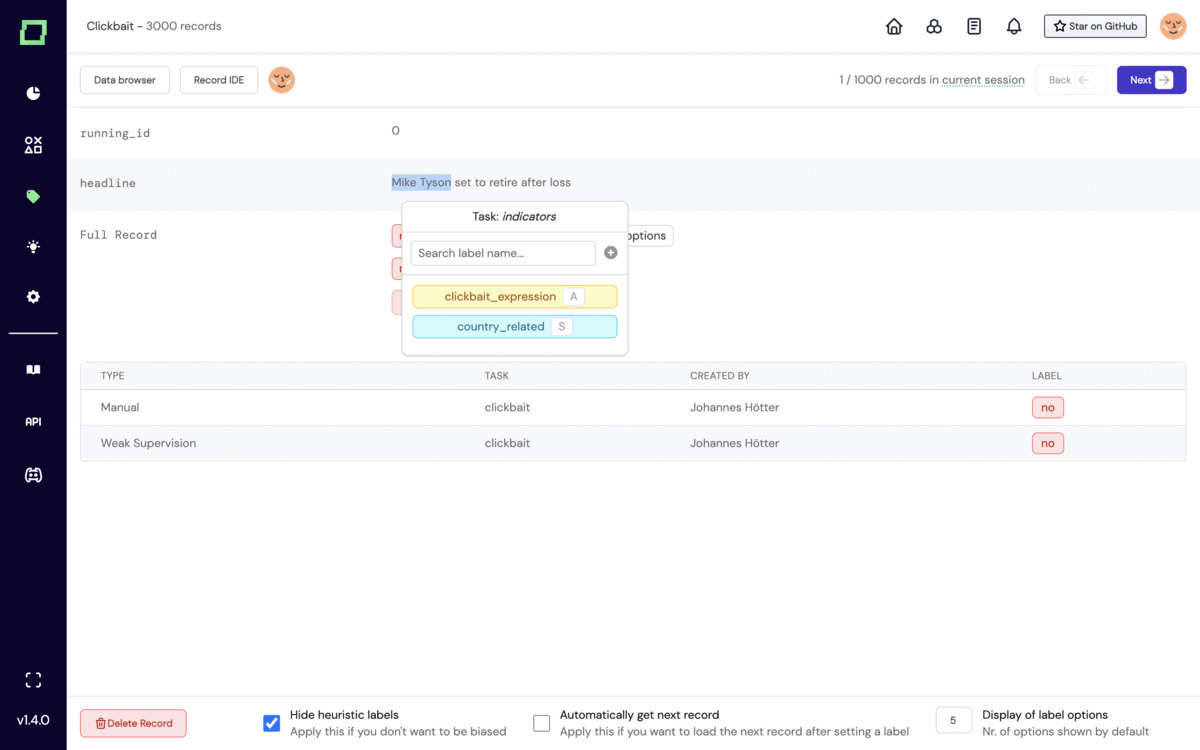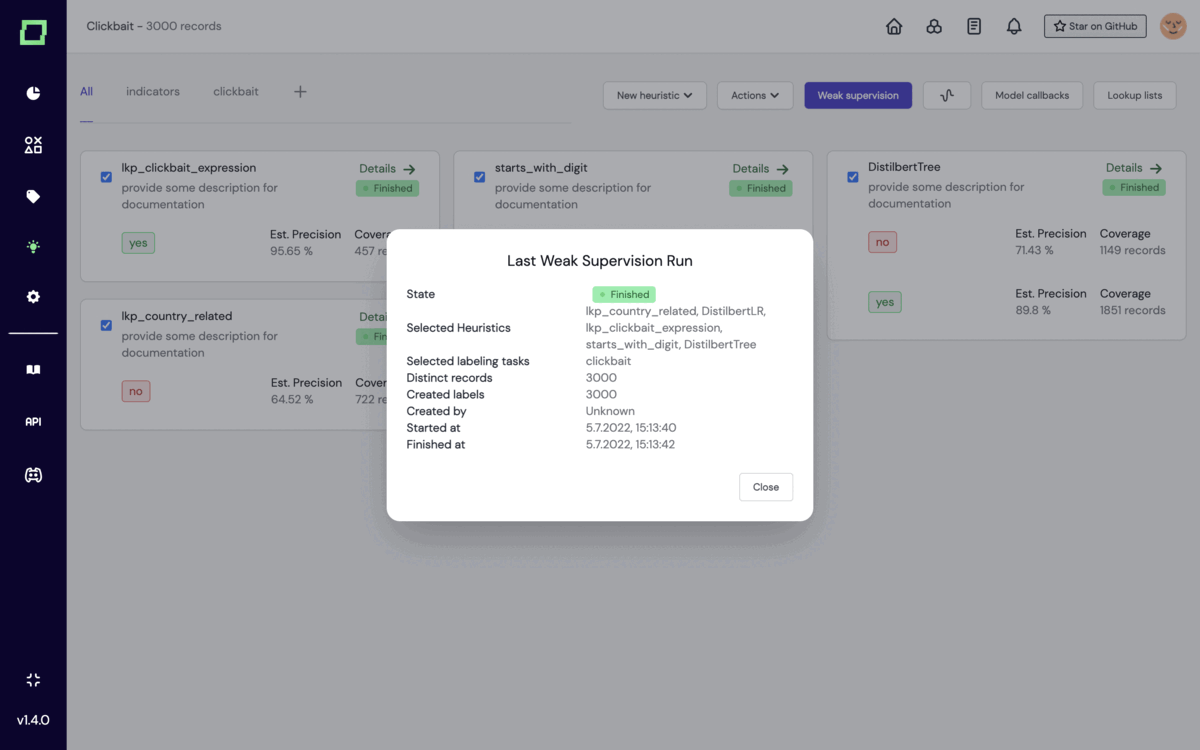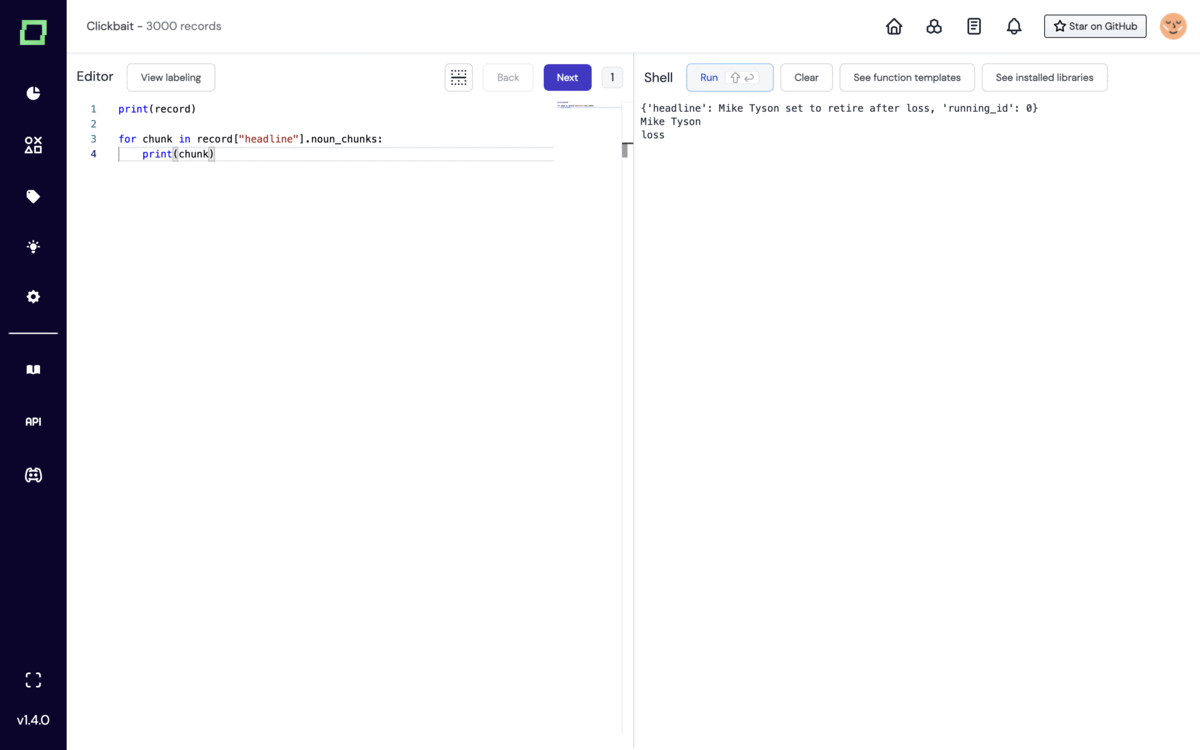
Kern AI: Example of Refinery in action Image Credits: Kern AI
Hötter said that a typical real-world use-case for the Kern AI platform involves companies’ internal tooling. For example, a logistics company might need to respond to a customer request such as “please ship 20 palettes to our plant in Gothenburg by tomorrow 4pm” — such time-sensitive requests need to be answered swiftly. The logistics company could use Kern AI to synchronize incoming requests with their transport management system (TMS), to automatically detect the intent and the requirements of the request.
“This is done by synchronizing the service inbox with our commercial product workflow, which then pushes the data to Refinery,” Hötter explained to TechCrunch. “Here, developers can use NLP techniques to analyze the request, and then push the structured extracted information directly to their TMS.”
So, in some ways this works in a similar way to something like Zapier, but rather than following a rules-based approach, it’s built for more complex natural-language understanding.
The state of play
In truth, there are myriad similar platforms out there already, spanning the entire proprietary and open source landscapes. These include Argilla, which recently raised a $1.6 million seed round of funding, and Heartex which closed a heftier $25 million tranche of funding last year for Labelstudio. And then there is Snorkel AI, a proprietary offering which has secured some $135 million in financing through its history.
So what, exactly, is Kern AI doing that’s different? Hötter says that it’s the only “open-core and modular full stack” currently on the market. By that he means that its platform can be used either as a developer-focused add-on plugged into existing labelling platforms such as Labelstudio, or it can be used to build entire data-centric NLP applications in their entirety.
“This means that you can either use Refinery as the application to merely manage and build your training data, for example if you’re a startup wanting to build a sophisticated NLP product and now need a great solution to build the data,” Hötter said. “Alternatively, you can also use the algorithms of Refinery to deploy a realtime API, and to orchestrate full workflows, which would cover the full value chain. Our goal is to bring the advancements of modern NLP to data teams regardless of their current tech stack, and thus our platform is modular.”
Kern AI currently counts some nine employees, working remotely for the most part but while maintaining a physical office in its native Bonn.
Prior to now, Kern AI had raised a small €550,000 ($587,000) pre-seed round of funding, and with a fresh $2.9 million in the bank, Hötter said the company plans to expand the platform’s feature-set to cover additional workflows including audio- and document-based data, and build products for a much broader range of industry use-cases. Hötter also said that they will expedite plans to make a free, personal tier generally available, as it’s currently only available on an invite basis.
Kern AI’s seed round was co-led by Seedcamp and Faber, with participation from Xdeck, Another.vc, and a handful of angel investors.
German startup Kern AI nabs seed funding for modular NLP development platform by Paul Sawers originally published on TechCrunch




{kind=link}