
DynamoFL, which offers software to bring large language models (LLMs) to enterprises and fine-tune those models on sensitive data, today announced that it raised $15.1 million in a Series A funding round co-led by Canapi Ventures and Nexus Venture Partners.
The tranche, with had participation from Formus Capital and Soma Capital, brings DynamoFL’s total raised to $19.3 million. Co-founder and CEO Vaikkunth Mugunthan says that the proceeds will be put toward expanding DynamoFL’s product offerings and growing its team of privacy researchers.
“Taken together, DynamoFL’s product offering allows enterprises to develop private and compliant LLM solutions without compromising on performance,” Mugunthan told TechCrunch in an email interview.
San Francisco-based DynamoFL was founded in 2021 by Mugunthan and Christian Lau, both graduates of MIT’s Department of Electrical Engineering and Computer Science. Mugunthan says that they were motivated to launch the company by a shared desire to address “critical” data security vulnerabilities in AI models.
“Generative AI has brought to the fore new risks, including the ability for LLMs to ‘memorize’ sensitive training data and leak this data to malicious actors,” Mugunthan said. “Enterprises have been ill-equipped to address these risks, as properly addressing these LLM vulnerabilities would require recruiting teams of highly specialized privacy machine learning researchers to create a streamlined infrastructure for continuously testing their LLMs against emerging data security vulnerabilities.”
Enterprises are certainly encountering challenges — mainly compliance-related — in adopting LLMs for their purposes. Companies are worried about their confidential data ending up with developers who trained the models on user data; in recent months, major corporations including Apple, Walmart and Verizon have banned employees from using tools like OpenAI’s ChatGPT.
In a recent report, Gartner identified six legal and compliance risks that organizations need to evaluate for “responsible” LLM risk, including LLMs’ potential to answer questions inaccurately (a phenomenon known as hallucination), data privacy and confidentiality and model bias (for example, when a model stereotypically associates certain genders with certain professions). The report notes that these requirements might vary depending on the state and country, complicating matters; California, for example, mandates that organizations must disclose when a customer is communicating with a bot.
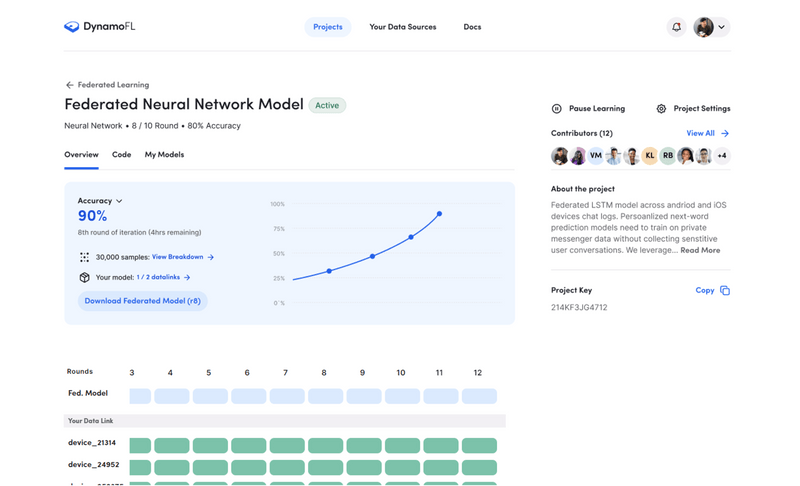
Image Credits: DynamoFL
DynamoFL, which is deployed on a customer’s virtual private cloud or on-premises, attempts to solve for these problems in a range of ways, including with an LLM penetration testing tool that detects and documents LLM data security risks like whether an LLM has memorized or could leak sensitive data. Several studies have shown that LLMs, depending on how they’re trained and prompted, can expose personal information — an obvious anathema to large firms working with proprietary data.
In addition, DynamoFL provides an LLM development platform that incorporates techniques aimed at mitigating model data leakage risks and security vulnerabilities. Using the platform, devs can integrate various optimizations into models, also, enabling them to run on hardware-constrained environments such as mobile devices and edge servers.
These capabilities aren’t particularly unique, to be clear — at least not on their face. Startups like OctoML, Seldon and Deci provide tools to optimize AI models to run more efficiently on a variety of hardware. Others, like LlamaIndex and Contextual AI, are focused on privacy and compliance — providing privacy-preserving ways to train LLMs on first-party data.
So what’s DynamoFL’s differentiator? The “thoroughness” of its solutions, Mugunthan argues. That includes working with legal experts to draft up how to use DynamoFL to develop LLMs in compliance with U.S., European and Asian privacy laws.
The approach attracted several Fortune 500 customers, particularly in the finance, electronics, insurance and automotive sectors.
“While products exist today to redact personally identifiable information from queries sent to LLM services, these don’t meet strict regulatory requirements in sectors like financial services and insurance, where redacted personally identifiable information is commonly reidentified through sophisticated malicious attacks,” he said. “DynamoFL has drawn upon its team’s expertise in AI privacy vulnerabilities to build the most comprehensive solution for enterprises seeking to satisfy regulatory requirements for LLM data security.”
DynamoFL doesn’t address one of the more sticky issues with today’s LLMs: IP and copyright risks. Commercial LLMs are trained on a large amount of internet data, and sometimes, they regurgitate this data — putting any company that uses them at risk of violating copyright.
But Mugunthan hinted at an expanded set of tools and solutions to come, fueled by DynamoFL’s recent funding.
“Addressing regulator demands is a critical responsibility for C-suite level managers in the IT department, particularly in sectors like financial services and insurance,” he said. “Regulatory non-compliance can result in irreparable damage to the trust of customers if sensitive information is leaked, carries severe fines and can result in major disruptions in the operations of an enterprise. DynamoFL’s privacy evaluation suite provides out-of-the-box testing for data extraction vulnerabilities and automated documentation required to meet security and compliance requirements.”
DynamoFL, which currently employs a team of around 17, expects to have 35 staffers by the end of the year.




{kind=link}